
This post was written by Lior Ben Zvi, Algo Team Leader at Start.io.
In the world of machine learning, we often hear about the importance of “accuracy,” but what if a super-accurate model could actually harm a business? This article explains a surprising truth from the world of digital advertising(AdTech): sometimes, a model that’s too good at predicting outcomes can become stuck in a rut. It becomes so good at predicting a reality it created that it stops exploring new opportunities. We learned that by intentionally adding a bit of randomness, our system found new ways to grow, proving that a model doesn’t have to be perfect to be successful.
In the world of applied machine learning (ML), a few words carry as much weight and as much misunderstanding as accuracy. For decades, accuracy (or its siblings: precision, recall, log-loss, area under the receiver operating characteristic curve (AUC), etc.) has been the North Star by which data scientists measure progress. If the curve on your validation set bends upward, or the error rate ticks downward, the celebration begins.
But after years of working in real-time inference systems, especially in AdTech where billions of micro-decisions cascade into macro-economic outcomes, I’ve come to a sobering realization: accuracy can become a trap. One that makes algorithms look “smarter” in offline benchmarks, while in production, they quietly underperform or even stagnate business growth. This isn’t just a philosophical claim. It’s rooted in mathematics, experimentation, and plenty of painful lessons from deploying models in dynamic environments. Let’s unpack why.
The Seduction of Accuracy:
At its core, these are very basic and standard functions. On one side are classification and ranking measures, such as accuracy, precision, recall, and AUC. Accuracy, f.e, measures the fraction of correct predictions:
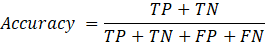
On the other hand, probabilistic and calibration measures like log-loss and Brier score, often minimized during training, measure how close your predicted distribution p̂(y|x) is to the true distribution p(y|x). In click-through rate (CTR) prediction, for example, you might use log-loss or Brier score:
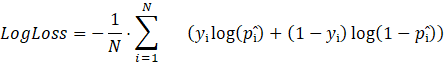
The issue described could come from each of the above options, and we often measure more than one. For simplicity, from now on, when we discuss prediction error, we will address the % gap between the number of predicted clicks and the number of actual clicks. If we predicted 100 clicks and got 150 clicks, we have 50% prediction error. In case of 50 clicks, we have (–50%) prediction error.
Understanding the Unique Nature of AdTech Data:
In AdTech, data behaves less like a clean lab sample and more like a bustling marketplace: constantly shifting, full of newcomers (which brings us to the well-known cold start problem), and dominated by a few big players while countless smaller ones sit quietly in the long tail. The big twist is that much of this data isn’t neutrally observed; it’s self-generated by the very models that decide who sees what, creating feedback loops. And unlike in academia, accuracy alone doesn’t pay the bills: profit, ROI, and business KPIs often matter more than being “mathematically right”. This unique blend makes AdTech data one of the most challenging and fascinating playgrounds for modeling.
The Self-Fulfilling Prophecy of Models:
Our team once built a sophisticated click-through rate (CTR) prediction algorithm. Offline, its results were stunning: prediction error stands at almost 2%, a massive statistical leap given the size of our datasets. We rolled it out expecting business metrics to follow suit: more impressions delivered efficiently, more clicks, more revenue. But the needle barely moved.
Why? Because our model had become a self-fulfilling prophecy.
When a model grows too “confident” and too consistent, it starts generating stable, predictable traffic. The ecosystem stabilizes around those predictions. We pat ourselves on the back because the model forecasts the same boring patterns it helped enforce. The paradox: the model becomes excellent at predicting a reality that it created. It doesn’t explore. It doesn’t discover. It doesn’t adapt.
Exploration vs. Exploitation:
This is where accuracy breaks down as a business KPI. From a decision-theory perspective, every algorithm faces the exploration–exploitation tradeoff. Exploitation means leaning into what you already know. If ad X achieves a 4% CTR, it will likely maintain its current performance. Exploration means deviating from the “rational” choice to probe for better opportunities. Mathematically, you can think of this as balancing expected reward with the variance of uncertainty. Pure accuracy optimizers minimize error but maximize stasis. Exploratory strategies accept small local losses to test the tail of the distribution. This is why reinforcement learning frameworks use concepts like epsilon-greedy policies: with probability ε, take a random action rather than the predicted best one. That noise isn’t a waste – it’s insurance against stagnation.
Introducing Chaos by Design:
We applied this principle by building what we half-jokingly called a ״Chaos Agent״. The Chaos Agent injected controlled randomness into our production system. In a small percentage of requests, instead of following the model’s top-ranked prediction, it deliberately flipped the decision, sometimes promoting an impression the model thought was weak, sometimes demoting one it thought was strong.
The percentage was small enough that short-term losses were negligible. But the long-term payoff was immense. We suddenly had fresh data from corners of the feature space the model would have otherwise ignored.
The results spoke for themselves:
24% growth in impressions
43% growth in clicks.
75% growth in net revenue.
Prediction error (our accuracy metrics representative) declined slightly (still below 10%), but the system’s business performance skyrocketed!
Unpacking the Drivers Behind the Results:
So, what actually drove these remarkable results? When we dug into the data, it turned out to be a mix of several factors. First, small dimensions that had previously been overlooked suddenly got their chance – the system picked up the signal and started sending them more and more traffic. Second, edge cases that the model had historically avoided due to lack of confidence (and data) began to receive meaningful exposure. You can even see this reflected in the fact that revenue grew much faster than impressions. Third, we finally gathered enough data on certain dimensions to recognize they weren’t profitable, so the system learned to bid less on them. The outcome: CTR climbed, because impressions grew more slowly than clicks – we effectively pruned wasteful traffic and shifted toward impressions that truly mattered.
Why Accuracy Misleads in Dynamic Systems:
The lesson here is fundamental: accuracy is a static measure applied to dynamic systems. In environments like AdTech, your predictions influence the very data distribution you later evaluate against. This phenomenon is known as performative prediction – the act of prediction changes the target. Optimizing for accuracy in such systems risks collapsing exploration, leading to local optima. In contrast, introducing structured randomness keeps the system alive, dynamic, and adaptable. That is, a model with a 10% prediction error is not necessarily worse than a model with a 2% in some instances.
A Mindset Shift for Practitioners:
Accuracy feels safe. It’s quantifiable and comparable. However, if we want machine learning to create value, not just explain the past, we need to adopt a mindset shift: accepting a little chaos. Controlled randomness uncovers opportunities hidden in the long tail. Think in terms of systems, not snapshots. Every prediction feeds back into the environment. Optimize for adaptability, not perfection. The world changes; your model must too!
Alternative Approaches:
In this case, the solution we presented was just one example; however, professional literature offers a rich toolbox for tackling such challenges. This is where the world of multi-armed bandits comes into play, a framework that elegantly balances exploration and exploitation in uncertain environments. Among the many approaches, Thompson Sampling stands out as both intuitive and mathematically powerful: by maintaining a Bayesian posterior distribution over possible outcomes, the algorithm randomly samples from that distribution to decide which “arm” to pull next. In practice, this means it naturally allocates more traffic to strategies that appear promising, while still reserving room for experimentation: mitigating the cold start problem and continuously adapting to evolving data.
Common Pitfalls
There are many common pitfalls, and we won’t cover them all here, but one is worth highlighting given our prior discussion of alternative solutions. Filtering algorithms are rarely perfect; for example, an accuracy of 80% means that 20% of samples are misclassified false positives (FP) or false negatives (FN). It’s tempting to view FPs as a form of “exploration”. If half of the errors are FPs (i.e., 10%), one might think this mimics ε-greedy exploration in a nearly perfect model. In practice, however, it doesn’t. False positives are often systematically biased, favoring certain types of segments and leaving coverage narrow, whereas true ε-greedy exploration introduces controlled randomness, ensuring broader and more balanced exploration. So, no matter what randomization or chaos method you choose to introduce into the system, it needs to be balanced.
Conclusion:
Accuracy will always have a place in our toolbox. But we must stop worshipping it as the supreme measure of success. In dynamic, real-world systems, an overly accurate model can paradoxically become brittle, conservative, and blind to new possibilities. This issue applies to any filtering or ranking metric, not just accuracy. The problem lies not in the metrics themselves, but in how they are applied. So, what’s the solution? Awareness, incorporating additional KPIs, and seeking creative alternatives. Our experience with the Chaos Agent reminded us that in both algorithms and life, progress often comes not from predicting the obvious, but from daring to test the uncertain. A 99% accurate model that never tries anything new? That’s not smart, that’s just scared. Sometimes, the smartest thing a model can do is to be a little bit wrong on purpose.


