
This article was written by Haim Ari, DevOps Architect at Start.io
I took the challenge to rewrite our entire Java platform in Rust. Bottom line, it took me 2.5 days without writing a single line of code. Claude Code did.
We had a battle-tested real-time bidding (RTB) platform, years of production hardening, nine external service integrations, compliance engines for GDPR, CCPA, COPPA, and TCF, plus adapters for couple of dozens of advertising partners. The kind of codebase that makes senior engineers wince when someone mentions “rewrite.”
And yet, 2.5 days later, it was rewritten in Rust. Full feature parity. The challenge is migration management.
Here is how I (we) did that:
The Numbers That Don’t Lie
Let me start with the raw output, because the numbers still surprise me:
| Metric | Value |
| Calendar time | January 7–9, 2026 |
| Total commits | 85 |
| Pull requests | 70 |
| Rust crates created | 12 |
| Source files written | 85+ |
| Final status | RTB_PARITY_COMPLETE |
Seventy pull requests in under three days. Each one was reviewed by an AI code review tooling, tested against CI, and merged. While I slept.
The Secret: A System, Not a Sprint
I didn’t achieve this by being a 10x developer. I achieved it by building a 10x development system.
The insight that changed everything: you can’t just tell Claude “rewrite this Java app in Rust” and expect coherent results. What you can do is architect a pipeline where AI operates autonomously within clear constraints, understanding the problem, planning the work, following instructions, and iterating until done.
My pipeline had four phases:
- Understand – Deep analysis of the existing codebase
- Plan – Structured proposal with explicit completion criteria
- Instruct – Teaching Claude how to work in my repository
- Execute – Autonomous iteration until parity achieved
Each phase was essential. Remove any one, and the whole thing collapses into endless manual intervention.
Phase 1: Understanding the Beast
Before you can rewrite something, you need to understand it. Our Java RTB codebase was massive — controllers, services, DAOs, partner adapters, compliance engines, multi-tier caching, the works.
I started with DeepWiki powered by Claude Opus. Point it at a GitHub repository, and it generates comprehensive documentation by analysing the entire codebase. Within minutes, I had architecture diagrams, component relationships, data flow documentation, and API endpoint mappings.
But raw documentation isn’t enough. To get more in-depth information, I created a Claude Skill to refine the DeepWiki output into an Analysis Document – a structured understanding of exactly what the Java system did and how it did it.
What emerged was a complete inventory: nine service integrations for configuration storage, distributed caching, IP geolocation, message queuing, event streaming, user enrichment, fraud detection, and ML model evaluation. Every external dependency is mapped. Every data flow is documented.
This analysis became the foundation for everything that followed.
Phase 2: Planning with OpenSpec
Here’s where most AI-assisted development falls apart: lack of structure.
You need a framework. I used OpenSpec – a specification-driven development approach where every change starts with a proposal. The proposal defines:
- Why we’re doing this (performance requirements, maintainability goals)
- What changes (all Java code replaced with Rust, same external API contracts, same partner integrations, same compliance behavior)
- Every component affected (RTB core, compliance layer, DSP integration, fraud detection, event production, caching, user enrichment, response building)
But the real magic was in the task breakdown. I created 19 phases with 180+ individual tasks:
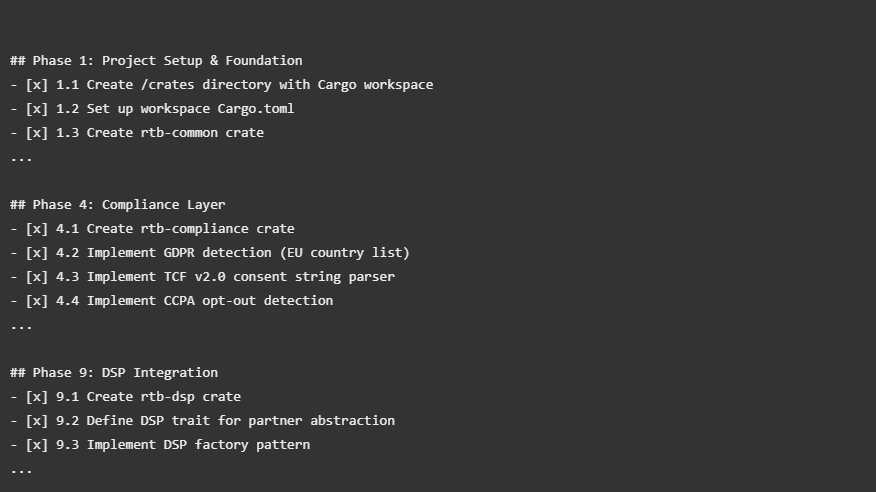
The Completion Criteria (This Was Key)
Here’s the insight that made autonomous operation possible. In the OpenSpec proposal, I defined exactly what “done” looks like:
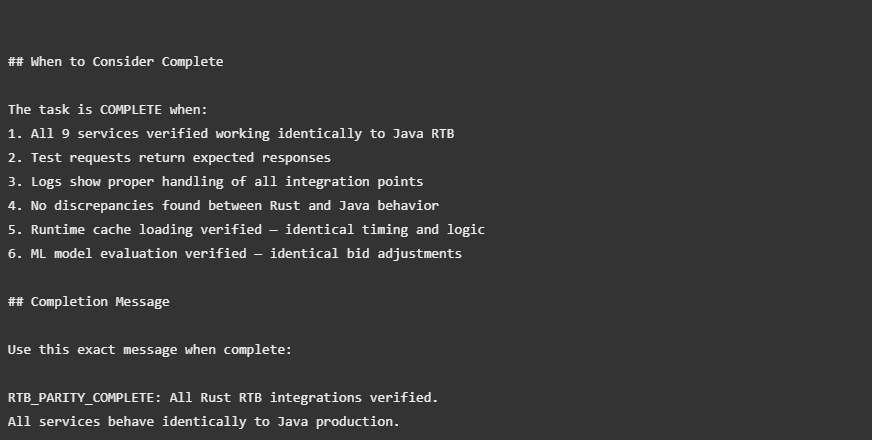
This wasn’t just documentation. This was programming Claude’s termination condition. It knew exactly when to stop.
Phase 3: Teaching Claude How to Work
The CLAUDE.md file is your instruction manual for AI. It tells Claude Code how to behave in your repository.
LSP Usage (Non-Negotiable)
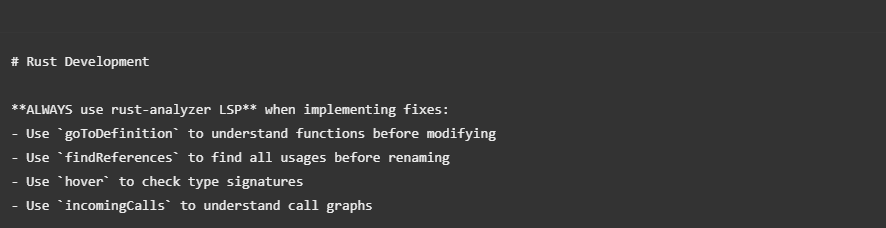
This single instruction prevented countless errors. Claude wasn’t guessing at type signatures — it was looking them up. The difference between “AI that guesses” and “AI that researches.”
The Testing Ritual

Every commit was clean. Every commit passed tests. No exceptions.
The Git Workflow
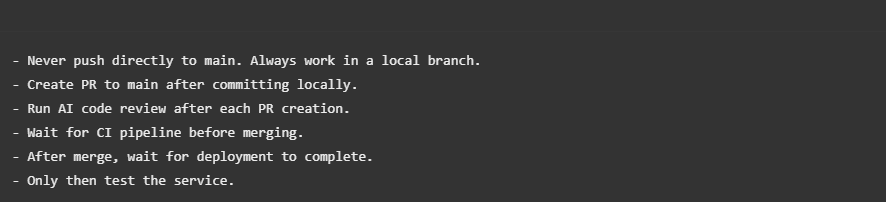
The AI code review loop was crucial. After pushing fixes, I had Claude explicitly trigger re-review, wait for new comments, and address them — repeating until clean. Quality gates maintained through 70 PRs.
Phase 4: The RALPH Loop (Where the Magic Happens)
The RALPH Loop (named after Ralph Wiggum from The Simpsons — because like Ralph, it just keeps going, blissfully unaware of obstacles) is an autonomous execution loop that let Claude Code work 24+ hours straight.
The Loop Definition
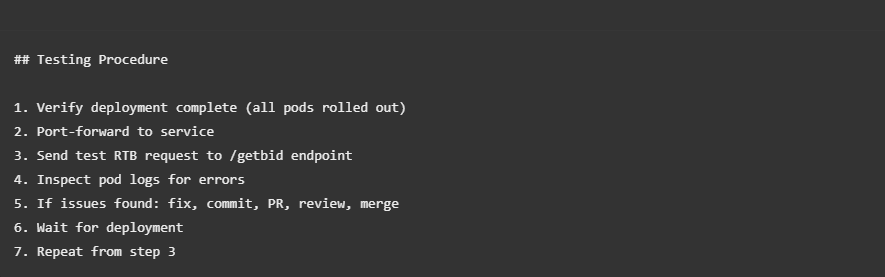
What Claude Did in Each Iteration
Each cycle discovered an issue, analyzed the root cause, implemented a fix, and verified the solution:
- Iteration 1: External service client failed – upgraded to newer client version
- Iteration 2: Data field names mismatched — corrected field mappings from Java
- Iteration 3: Cache key format wrong – fixed key formatting pattern
- Iteration 4: Partner DNS failures for defunct domains – added blocklist configuration
- Iteration 5: Cryptographic signing missing – implemented HMAC-SHA256
Each issue discovered → analyzed → fixed → tested → reviewed → deployed.
All while I slept.
The One Time It Failed
Transparency matters. The loop wasn’t perfect.
Around hour 18, I ran out of API credits. The max-iterations limit was also reached simultaneously. In another instance, a simple configuration error caused the loop to get stuck.
The recovery:
- Topped up credits
- Restarted the RALPH loop
- Claude picked up exactly where it left off since – OpenSpec tasks tracked state – and since I had a progress.txt file that is used specifically for RALPH to track the loop state.
- Continued to completion
Lesson learned: Budget for credits. Set iteration limits high. The loop is resilient if you let it resume. Make sure to keep track automatically in state files.
The Modular Architecture That Emerged
The Rust workspace structure Claude built was clean and well-organized — 12 separate crates, each with a clear responsibility. The architecture followed domain-driven boundaries: a core server crate for HTTP handling and request orchestration, separate crates for business logic domains (compliance, partner integrations, fraud detection), infrastructure concerns (caching, configuration, event production), and shared utilities.
What impressed me most was how Claude naturally gravitated toward idiomatic Rust patterns — trait-based abstractions for partner integrations, proper error handling with custom types, and async-first design throughout.
85+ source files across 12 crates. All generated, reviewed, and tested by the RALPH loop.
What Made This Possible
1. Structure Over Speed
I spent time upfront on OpenSpec proposals and task breakdowns. This felt slow but paid off exponentially. Claude never wandered — it always knew the next task.
2. Explicit Completion Criteria
“Keep working until X” only works if X is precisely defined. The RTB_PARITY_COMPLETE message format was that definition.
3. The Review Loop
AI code review caught issues I would have missed. The re-trigger pattern kept quality high through 70 PRs.
4. LSP Integration
Telling Claude to use goToDefinition and findReferences transformed it from “AI that guesses” to “AI that looks things up.” Huge difference.
5. Letting Go
The hardest part? Walking away from the keyboard. Trusting the system. Sleeping while the loop ran.
Reproducible Results
This isn’t magic. It’s methodology. Here’s how you can replicate it:
Document everything first — Use documentation generators to create baseline analysis. Refine with Claude into a structured analysis document capturing all integrations, data flows, edge cases, and configuration patterns.
Write the proposal — Define why you’re doing this, what changes, every component affected, success criteria (be SPECIFIC), and the exact “done” message.
Create your instruction file — Include language-specific tooling (LSP commands), pre-commit checks, git workflow, review process, and testing requirements.
Define your execution loop — Specify how to test the system, what logs to check, what “working” looks like, and when to stop.
Start the loop and step away — Trust the system. Check in periodically. Top up credits if needed.
Final Thoughts
2.5 days. ~85 commits. ~70 pull requests. 12 crates. ~85 source files.
One developer. One AI. One methodology.
The future of software development isn’t about typing faster. Actually, it’s not even about writing code.
It’s about teaching machines to work while we think about building systems that compound effort. About defining problems so precisely that solutions emerge automatically.
You should define goals, instruct the path, implement verification tooling, and create your own system that teaches itself how to work correctly — then trust it.
Just like a development team manager doesn’t read every line of code that each team member writes, you should learn to specify, trust, and validate.
Yes, you’re responsible for the code that ships. But you don’t need to write it anymore. And you shouldn’t have to babysit every line generated by your AI agent, either.
Finding the best ways to put together the correct tooling and safeguards — that is the future of human developers.
I didn’t rewrite a Java RTB platform in Rust.
I built a system that did.
About the Author: Haim Ari is a DevOps engineer exploring the intersection of AI-assisted development and production systems. This article was co-authored with Claude.


