By: Eyal Peer, Big Data Team Lead
Motivation
We had a case in which we needed to process a large amount of data (10B events) in a short time (30 minutes) from S3 bucket. The processing logic – standard lookup conversion and geo enrichment – is not the challenge here.
The main challenge is that most of the data (99%) arrives once a day, so scaling up and down must be quick.
Using our on-prem clusters (Flink or Spark) resulted in many ci/cd difficulties.
Although both frameworks offer scalability options, in practice, adding/removing nodes from a cluster is not trivial.
Another option we checked was using serverless framework, for example, Lambda function. This option is a best fit to our use case, however its costs are significantly higher.
And then we discovered Argo Workflows.
What is Argo?
“Argo is an open-source suite of projects that helps developers deliver software more rapidly and safely.” (According to getambassdor.io – the first Google result😊).
In our infrastructure, we use Argo as a CD tool to ensure production is synced with Git, and for monitoring and self-healing of k8s services. It’s part of our git-ops solution, which also includes git (obviously) and CodeFresh.
Ok, so what is an Argo Workflow?
“Argo Workflows is an open-source container-native workflow engine for orchestrating parallel jobs on Kubernetes.” (Again – thanks, Google).
In other words, it’s a framework that orchestrates and helps you to run jobs in k8s.
A workflow may contain one or more steps.
Using Argo, we can even build DAG (Directed Acyclic Graph), like in the very popular Apache Airflow solution. However, this is not relevant for our use case.
Sounds like Argo Workflows is an interesting candidate here.
Back to our story:
We decided to write the inner code of the workflows in Go. That way, we can make use of parallelism and concurrency easily and more efficiently using Go runtime.
Also, the warmup of Go app is significantly faster than Java. This is important to note when planning to launch a large number of pods in short amounts of time.
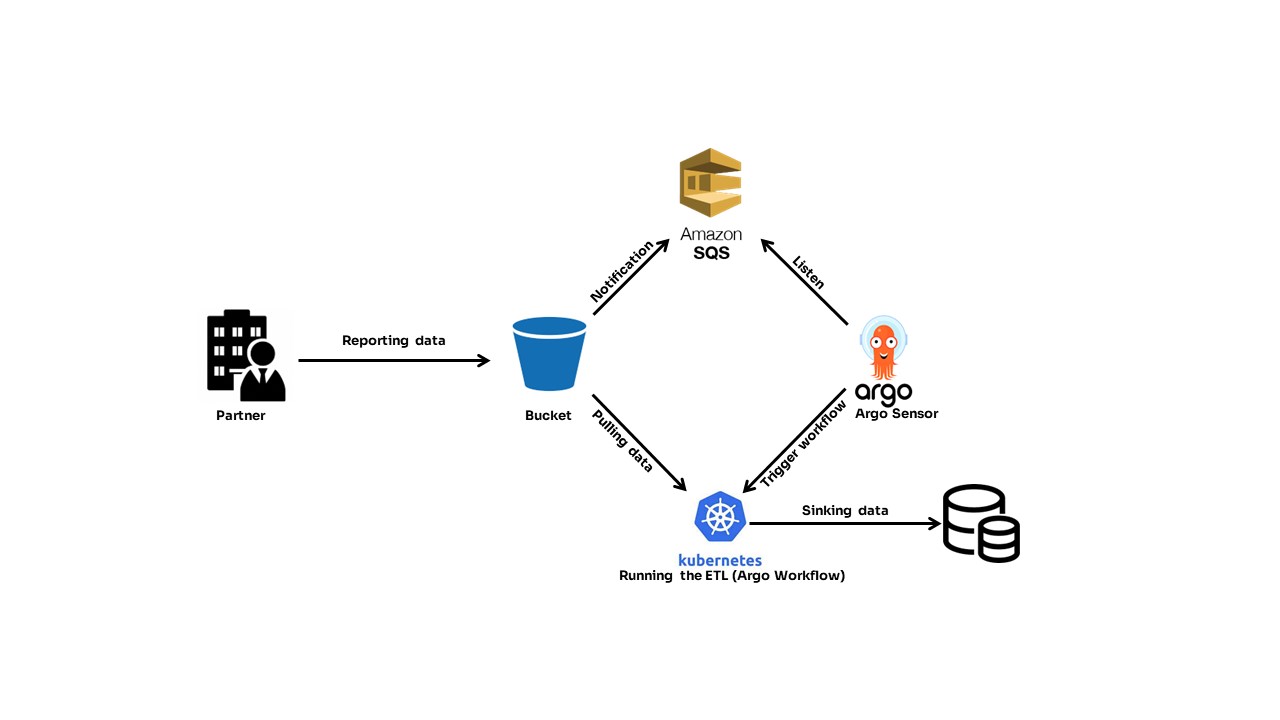
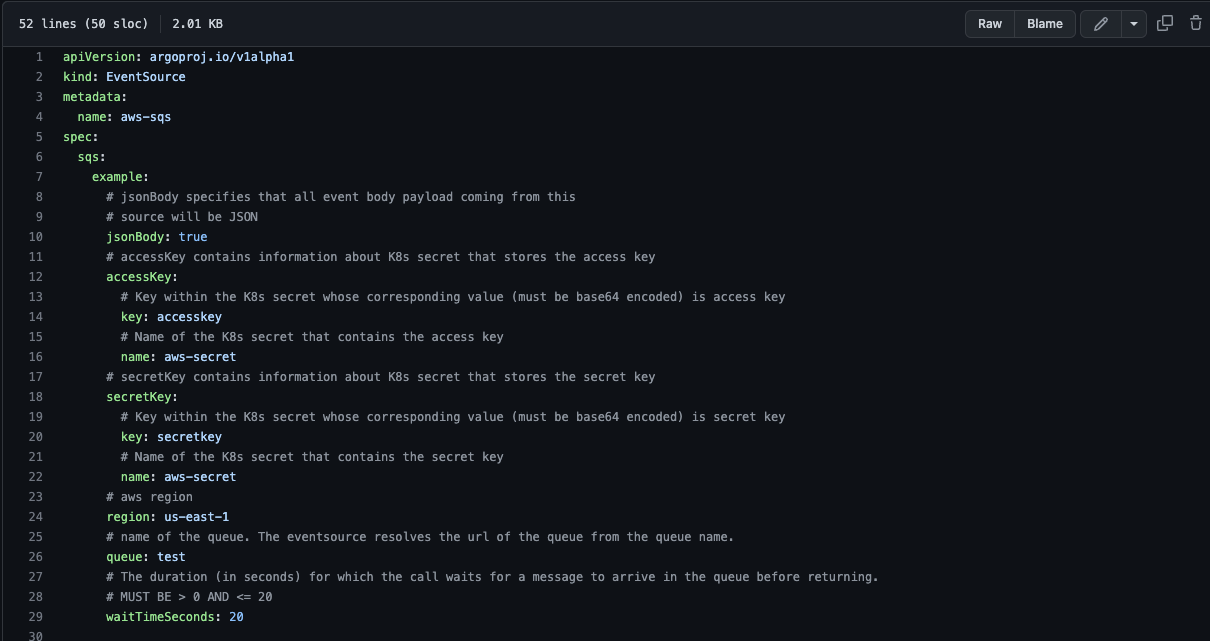
As I mentioned, the data entry point is S3 bucket. We configured the bucket to notify SQS about new files, so each new data arrival triggers a new message in SQS. This is a very widely used option in AWS, and I bet it’s available in other cloud providers.
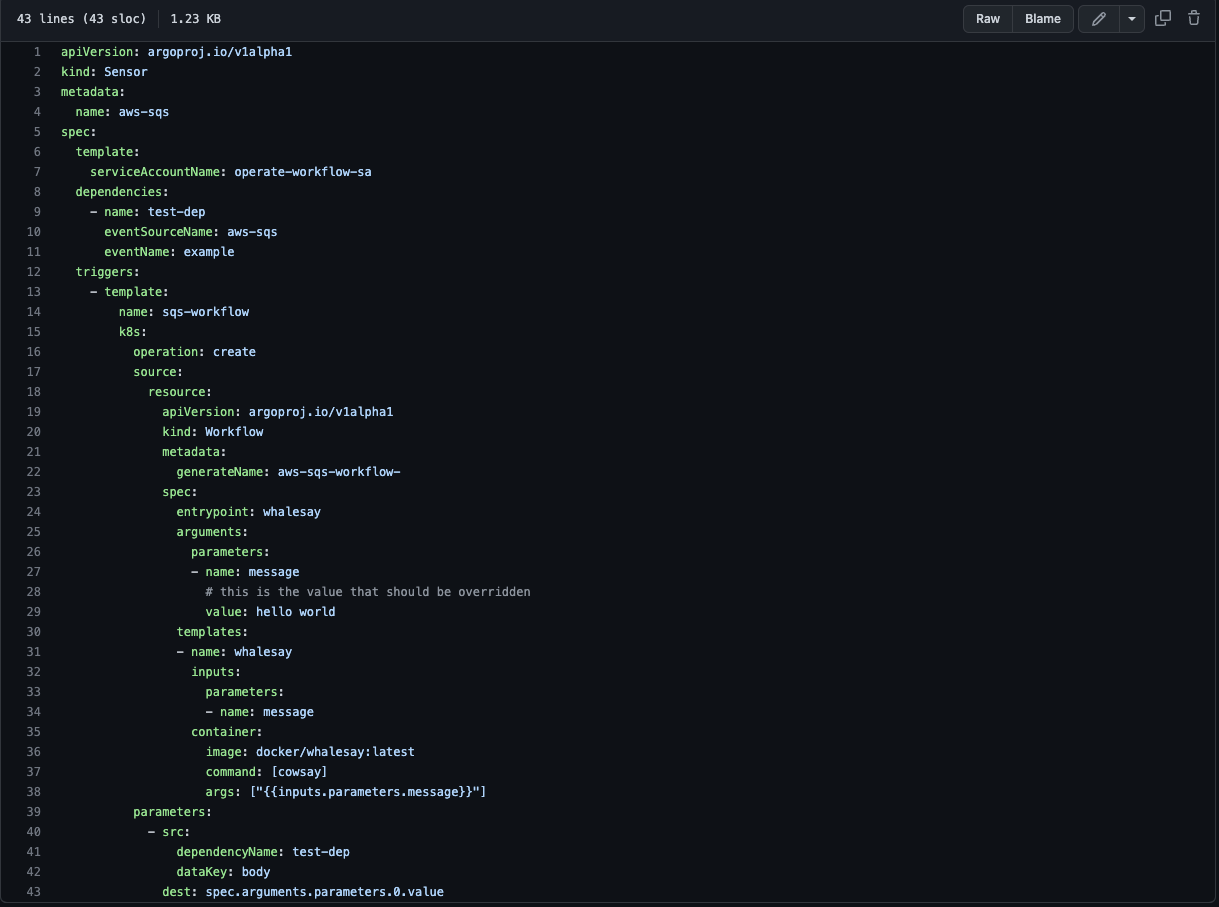
Then, we used Argo to define a sensor (Argo Sensor), which listens for a new message in the defined SQS.
In case of new messages, the sensor triggers workflows, one per message.
We can limit the resources from the k8s side or the Argo side.
Terminology
The design is very simple: configuring Sensor and event source. Let’s review those terms. (This section is copied from https://argoproj.github.io/argo-events/).
EventSource: Defines the configurations required to consume events from external sources, like SNS, SQS, GCP PubSub, Webhooks, etc.
It further transforms the events into cloudevents and dispatches them over to the eventbus. (https://argoproj.github.io/argo-events/concepts/event_source/)
Sensor: Defines a set of event dependencies (inputs) and triggers (outputs). It listens to events on the eventbus and acts as an event dependency manager to resolve and execute the triggers.
Why do I find Argo Workflows so useful?
Using k8s, we can enjoy the benefits of Argo:
- It is easy to control and manage resources – scalability is easy to accomplish.
- Costs remain lower. In serverless (Lambda function etc.), the solution may be easy, but costs are significantly higher.
- Flexibility in multi-cloud and multi-sites – no cloud vendor locking and can be run on inhouse servers.
- Since k8s has become so widely used and kind of standard, we can use the built-in k8s tools we already have on this cluster: Prometheus, Loki, internal services, Dbs and so on.
- Development time is short – setup is fairly easy and straightforward.
Conclusion
Currently, most of our data pipelines are stream based, and for that purpose, I will keep using Spark/Flink (in our case Flink 😊). However, for huge bursts of data that do not have continual behavior, I strongly recommend considering Argo Workflows.
By: Eyal Peer, Big Data Team Lead